Connecting Apache Kafka® to All Your Systems
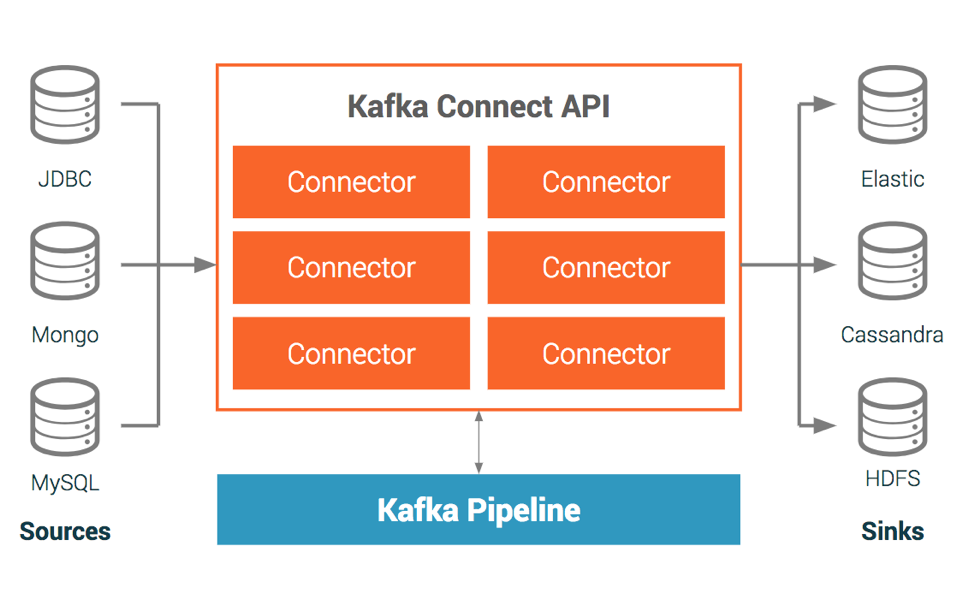
The Kafka Connect API is an interface that simplifies and automates the integration of a new data source or sink to your Kafka cluster. The most popular data systems have connectors built by either Confluent, its partners, or the Kafka community and you can find them in Confluent Hub. You can leverage this work to save yourself time and energy. There are also tools, like Confluent Control Center and Confluent CLI make it easy to manage and monitor Connectors.
Confluent Hub Advantage

Confluent Hub provides the only supported, managed and curated repository of connectors and other components in the Apache Kafka ecosystem. Confluent Hub provides the following set of components at various levels of support:
- Confluent Connectors, supported by Confluent
- Verified and Gold Connectors, supported by Confluent partners.
- Community Connectors, supported by the community. Patches are welcome.
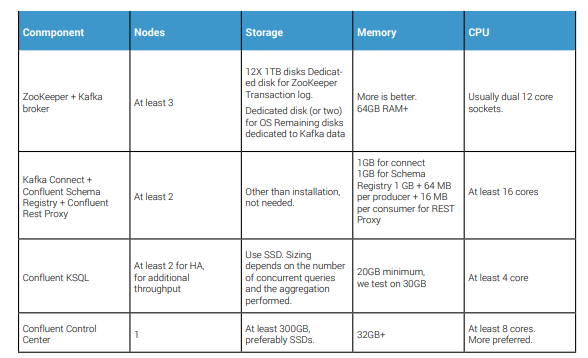
Large Cluster Reference Architecture

Small Cluster
Public Cloud Deployment
Today many deployments run on public clouds where node sizing is more flexible than ever before. The hardware recommendations
discussed earlier are applicable when provisioning cloud instances. Special considerations to take into account are:
• Cores: Take into account that cloud providers use “virtual” cores when sizing machines. Those are typically weaker
than modern cores you will use in your data center. You may need to scale the number of cores up when planning cloud
deployments.
• Network: Most cloud providers only provide 10GbE on their highest tier nodes. Make sure your cluster has sufficient nodes
and network capacity to provide the throughput you need after taking replication traffic into account.
• Below are some examples of instance types that can be used in various cloud providers. Note that cloud offerings
continuously evolve and there are typically variety of nodes with similar characteristics. As long as you adhere to the
hardware recommendations, you will be in good shape. The instance types below are just examples.
While the examples below show each component on a separate node, some operations teams prefer to standardize on a single instance
type. This approach makes automation easier, but it does require standardizing on the largest required instance type. In this case, you
can choose to co-locate some services together, as long as there are sufficient resources for all components on the instance.
You’ll need multiple instances of each node. Previous recommendations regarding number of Kafka brokers, Confluent REST Proxy
servers, Kafka Connect workers, etc still apply

Streams Architecture
This section describes how Kafka Streams works underneath the covers.
Kafka Streams simplifies application development by building on the Apache Kafka® producer and consumer APIs, and leveraging the native capabilities of Kafka to offer data parallelism, distributed coordination, fault tolerance, and operational simplicity.
Here is the anatomy of an application that uses the Kafka Streams API. It provides a logical view of a Kafka Streams application that contains multiple stream threads, that each contain multiple stream tasks.

Processor Topology
A processor topology or simply topology defines the stream processing computational logic for your application, i.e., how input data is transformed into output data. A topology is a graph of stream processors (nodes) that are connected by streams (edges) or shared state stores. There are two special processors in the topology:
- Source Processor: A source processor is a special type of stream processor that does not have any upstream processors. It produces an input stream to its topology from one or multiple Kafka topics by consuming records from these topics and forward them to its down-stream processors.
- Sink Processor: A sink processor is a special type of stream processor that does not have down-stream processors. It sends any received records from its up-stream processors to a specified Kafka topic.
A stream processing application – i.e., your application – may define one or more such topologies, though typically it defines only one. Developers can define topologies either via the low-level Processor API or via the Kafka Streams DSL, which builds on top of the former.

A processor topology is merely a logical abstraction for your stream processing code. At runtime, the logical topology is instantiated and replicated inside the application for parallel processing (see Parallelism Model).
Event-Driven Microservice example
Java
The Event-Driven Microservice example implements an Orders Service that provides a REST interface to POST and GET orders. Posting an order creates an event in Kafka, which is picked up by three different validation engines: a Fraud Service, an Inventory Service, and an Order Details Service. These services validate the order in parallel, emitting a PASS or FAIL based on whether each validation succeeds.
ZooKeeper Security
You can enable security in ZooKeeper by using the examples below. For a complete Confluent Platform security example, see the Security Tutorial.
Enable ZooKeeper Authentication with SASL
Enable ZooKeeper authentication with SASL by using one of these methods.
- Add the following to
zookeeper.propertiesto enable SASL while still allowing connection without authentication:authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
- Add the following to ZooKeeper JVM command line:
-Dzookeeper.authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
Require All Connections to use SASL Authentication
Add the requirement that all connections must use SASL authentication by using one of these methods.
- Add the following to
zookeeper.properties:requireClientAuthScheme=sasl
- Add the following to ZooKeeper JVM command line:
-Dzookeeper.requireClientAuthScheme=sasl
SASL with Digest-MD5
Here is an example of a ZooKeeper node JAAS file:
Server {
org.apache.zookeeper.server.auth.DigestLoginModule required
user_super="adminsecret"
user_bob="bobsecret";
};
Here is an example of a ZooKeeper client JAAS file, including brokers and admin scripts like kafka-topics:
Client {
org.apache.zookeeper.server.auth.DigestLoginModule required
username="bob"
password="bobsecret";
};
If your Kafka broker already has a JAAS file, this section must be added to it.
SASL with Kerberos
Here is an example of ZooKeeper node JAAS file:
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/path/to/server/keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/yourzkhostname@EXAMPLE.COM";
};
Here is an example of a ZooKeeper client JAAS file, including brokers and admin scripts like kafka-topics:
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_server.keytab"
principal="kafka/kafka1.hostname.com@EXAMPLE.COM";
};
N
Kafka Connect Security
Encryption
If you have enabled SSL encryption in your Apache Kafka® cluster, then you must make sure that Kafka Connect is also configured for security. Click on the section to configure encryption in Kafka Connect:
Authentication
If you have enabled authentication in your Kafka cluster, then you must make sure that Kafka Connect is also configured for security. Click on the section to configure authentication in Kafka Connect:
Separate principals
Within the Connect worker configuration, all properties having a prefix of
producer. and consumer. are applied to all source and sink connectors created in the worker. The admin. prefix is used for error reporting in sink connectors. The following describes how these prefixes are used:- The
consumer.prefix controls consumer behavior for sink connectors. - The
producer.prefix controls producer behavior for source connectors. - Both the
producer.andadmin.prefixes control producer and client behavior for sink connector error reporting.
You can override these properties for individual connectors using the
producer.override., consumer.override., and admin.override. prefixes. This includes overriding the worker service principal configuration to create separate service principals for each connector. Overrides are disabled by default. They are enabled using the connector.client.config.override.policy worker property. This property sets the per-connector overrides the worker permits. The out-of-the-box (OOTB) options for the override policy are:-
connector.client.config.override.policy=None- Default. Does not allow any configuration overrides.
-
connector.client.config.override.policy=Principal- Allows overrides for the
security.protocol,sasl.jaas.config, andsasl.mechanismconfiguration properties, using theproducer.override.,consumer.override, andadmin.overrideprefixes.
-
connector.client.config.override.policy=All- Allows overrides for all configuration properties using the
producer.override.,consumer.override, andadmin.overrideprefixes.
Authorization using ACLs
Apache Kafka® ships with a pluggable, out-of-box Authorizer implementation that uses Apache ZooKeeper™ to store all the ACLs. It is important to set ACLs because otherwise access to resources is limited to super users when an Authorizer is configured. The default behavior is that if a resource has no associated ACLs, then no one is allowed to access the resource, except super users.
You can also use the Kafka AdminClient API to manage ACLs.
See also
For an example that shows this in action, see the Confluent Platform demo. Refer to the demo’s docker-compose.yml for a configuration reference.
Broker Configuration
Authorizer
To enable ACLs, you must configure an Authorizer. Kafka provides a simple authorizer implementation, and to use it, you can add the following to
server.properties:authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
Note
You can also use the commercially licensed LDAP authorizer to enable LDAP-group based ACLs in addition to user-based ACLs.
Super Users
By default, if no resource patterns match a specific resource, then the resource has no associated ACLs, and therefore no one other than super users are allowed to access the resource. If you want to change that behavior, you can include the following in
server.properties:allow.everyone.if.no.acl.found=true
You can also add super users in
server.properties like the following (note that the delimiter is semicolon since SSL user names may contain comma):super.users=User:Bob;User:Alice
KSQL Components
KSQL has these main components:
- KSQL engine – processes KSQL statements and queries
- REST interface – enables client access to the engine
- KSQL CLI – console that provides a command-line interface (CLI) to the engine
- KSQL UI – enables developing KSQL applications in Confluent Control Center
KSQL Server comprises the KSQL engine and the REST API. KSQL Server instances communicate with the Kafka cluster, and you can add more of them as necessary without restarting your applications.

- KSQL Engine
- The KSQL engine executes KSQL statements and queries. You define your application logic by writing KSQL statements, and the engine builds and runs the application on available KSQL servers. Each KSQL server instance runs a KSQL engine. Under the hood, the engine parses your KSQL statements and builds corresponding Kafka Streams topologies.The KSQL engine is implemented in the KsqlEngine.java class.
- KSQL CLI
- The KSQL CLI provides a console with a command-line interface for the KSQL engine. Use the KSQL CLI to interact with KSQL Server instances and develop your streaming applications. The KSQL CLI is designed to be familiar to users of MySQL, Postgres, and similar applications.The KSQL CLI is implemented in the io.confluent.ksql.cli package.
- REST Interface
- The REST server interface enables communicating with the KSQL engine from the CLI, Confluent Control Center, or from any other REST client. For more information, see KSQL REST API Reference.The KSQL REST server is implemented in the KsqlRestApplication.java class.
When you deploy your KSQL application, it runs on KSQL Server instances that are independent of one another, are fault-tolerant, and can scale elastically with load. For more information, see KSQL Deployment Modes.
KSQL Language Elements
Like traditional relational databases, KSQL supports two categories of statements: Data Definition Language (DDL) and Data Manipulation Language (DML).
These categories are similar in syntax, data types, and expressions, but they have different functions in KSQL Server.
- Data Definition Language (DDL) Statements
- Imperative verbs that define metadata on the KSQL server by adding, changing, or deleting streams and tables. Data Definition Language statements modify metadata only and don’t operate on data. You can use these statements with declarative DML statements.The DDL statements include:
- CREATE STREAM
- CREATE TABLE
- DROP STREAM
- DROP TABLE
- CREATE STREAM AS SELECT (CSAS)
- CREATE TABLE AS SELECT (CTAS)
- Data Manipulation Language (DML) Statements
- Declarative verbs that read and modify data in KSQL streams and tables. Data Manipulation Language statements modify data only and don’t change metadata. The KSQL engine compiles DML statements into Kafka Streams applications, which run on a Kafka cluster like any other Kafka Streams application.The DML statements include:
- SELECT
- INSERT INTO
- CREATE STREAM AS SELECT (CSAS)
- CREATE TABLE AS SELECT (CTAS)
The CSAS and CTAS statements occupy both categories, because they perform both a metadata change, like adding a stream, and they manipulate data, by creating a derivative of existing records.
For more information, see KSQL Syntax Reference.
KSQL Deployment Modes
You can use these modes to deploy your KSQL streaming applications:
- Interactive – data exploration and pipeline development
- Headless – long-running production environments
In both deployment modes, KSQL enables distributing the processing load for your KSQL applications across all KSQL Server instances, and you can add more KSQL Server instances without restarting your applications.