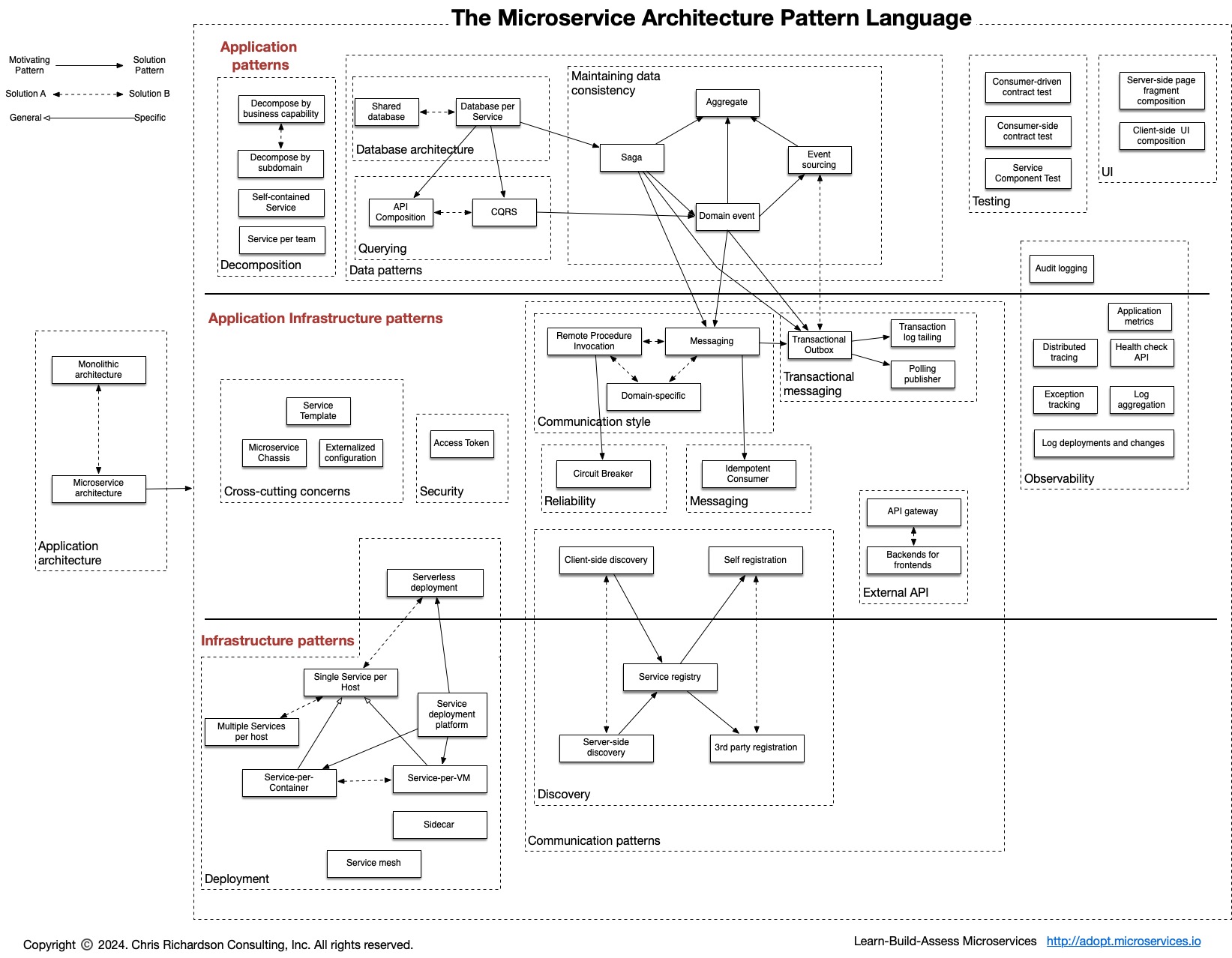
The Microservices Design Pattern
Microservice Design Patterns for Performance Monitoring
Monitoring the performance is an important aspect for a successful microservice architecture. It helps calculate the efficiency and understand any drawbacks which might be slowing the system down. Remember the following patterns related to observability for ensuring a robust microservice architecture design.
1. Log Aggregation
When we refer to a microservice architecture we are referring to a refined yet granular architecture where an application is consisting a number of microservices. These microservices run independently and simultaneously as supporting multiple services as well as their instances across various machines. Every service generates an entry in the logs regarding its execution. How can you keep a track for numerous service related logs? This is where log aggregation steps in. As a best practice to prevent from chaos, you should be having a master logging service. This master logging service should be responsible for aggregating the logs from all the microservice instances. This centralized log should be searchable, making it easier to monitor.
2. Synthetic Monitoring a.k.a Semantic Monitoring
As I explained previously, monitoring is a painful but indispensable task for a successful microservice architecture. With simultaneous execution of hundreds of services it becomes troublesome to pinpoint the root area responsible for the failure in log registry. Synthetic monitoring gives a helping hand. When you perform automated test then synthetic monitoring helps to regularly map the results in comparison to the production environment. User gets alerted if a failure is generated. Using Semantic Monitoring you can aim for 2 things using a single arrow
- Monitoring automated test cases.
- Detecting Production failures in terms of business requirements.
3. API Health Check
Microservice architecture design promotes services which are independent of each other to avoid any delay in the system. APIs as we know serve as the building blocks of an online connectivity. It is imperative to keep a health check on your APIs on regular basis to realize any roadblock. It is often observed that a microservice is up and running yet incapacitated for handling requests. This can be due to many factors:
- Server Loads
- User Adoption
- Latency
- Error Logging
- Market Share
- Downloads
In order to overcome this scenario we should ensure that every service running must have a specific health check API endpoint. For example: HTTP/health when appended at the end of every service will return the health status for respective service instance. A service registry periodically appeals to the health check API endpoint to perform a health scan. The health check would provide you with the information on the below-mentioned:
- A logic that is specific to your application.
- Status of the host.
- Status of the connections to other infrastructure or connection to any service instance.
Breaking it all down to Business Capability
The process of ‘decomposing’ a monolithic architecture into a microservice needs to follow certain parameters. These parameters have a different basis. Today we will look at the decomposition of the microservice design patterns which leave a lasting impact.
1. Unique Microservice for each Business Capability
A microservice is as successful as its combination of high cohesion and loose coupling. Services need to be loosely coupled while keeping the function of similar interests together. But how do we do it? How do we decompose a software system into smaller independent logical units?
We do so by defining the scope of a microservice to support a specific business capability.
We do so by defining the scope of a microservice to support a specific business capability.
For Example –
In every organization, there are different departments that come together as one. These include technical, marketing, PR, sales, service, and maintenance. To picture a microservice structure these different domains would each be the microservices and the organization will be the system.
So an Inventory management is responsible for all the inventories. Similarly, Shipping management will handle all the shipments and so on.
In every organization, there are different departments that come together as one. These include technical, marketing, PR, sales, service, and maintenance. To picture a microservice structure these different domains would each be the microservices and the organization will be the system.
So an Inventory management is responsible for all the inventories. Similarly, Shipping management will handle all the shipments and so on.
To maintain efficiency and foresee growth, the best solution is to decompose the systems using business capability. This includes classification into various business domains which are responsible to generate value in their own capabilities.
2. Microservices around similar Business Capability
Despite segregating on the basis of business capabilities, microservices often come up with a greater challenge. What about the common classes among the services? Well, decomposing these classes known as ‘God Classes’ needs intervention. For example, in case of an e-commerce system, the order will be common to several services such as order number, order management, order return, order delivery etc. To solve this issue, we turn to a common microservice design principle known as Domain-Driven Design (DDD).
In Domain-Driven Design, we use subdomains. These subdomain models have defined scope of functionality which is known as bounded context. This bounded context is the parameter used to create each microservice thus overcoming the issues of common classes.
3. Strangler Vine Pattern
While we discuss decomposition of a monolithic architecture, we often miss out the struggle of converting a monolithic system to design microservice architecture. Without hampering the working, converting can be extremely tough. And to solve this problem we have the strangler pattern, based on the vine analogy. Here is what the Strangler patterns mean in Martin Fowler’s words:
“One of the natural wonders of this area [Australia] is the huge strangler vines. They seed in the upper branches of a fig tree and gradually work their way down the tree until they root in the soil. Over many years they grow into fantastic and beautiful shapes, meanwhile strangling and killing the tree that was their host.”
Strangler pattern is extremely helpful in case of a web application where breaking down a service into different domains is possible. Since the calls go back and forth, different services live on different domains. So, these two domains exist on the same URI. Once the service has been reformed, it ‘strangles’the existing version of the application. This process is followed until the monolith doesn’t exist.
Microservice Design Patterns for Optimizing Database Storage
For a microservice architecture, loose coupling is a basic principle. This enables deployment and scalability of independent services. Multiple services might need to access data not stored in their unit. But due to loose coupling, accessing this data can be a challenge. Mainly because different services have different storage requirements and access to data is limited in microservice design. So, we look at some major database design patterns as per different requirements.
1. Individual Database per Service
Usually applied in Domain Driven Designs, one database per service articulates the entire database to a specific microservice. Due to the challenges and lack of accessibility, a single database per service needs to be designed. This data is accessible only by the microservice. This database has limited access for any outside microservices. The only way for others to access this data is through microservice API gateways.
2. Shared Database per Service
In Domain Driven Design, a separate database per service is feasible, but in an approach where you decompose a monolithic architecture to microservice, using a single database can be tough. So while the process of decomposition goes on, implementing a shared database for a limited number of service is advisable. This number should be limited to 2 or 3 services. This number should stay low to allow deployment, autonomy, and scalability.
3. Event Sourcing Design Pattern
According to Martin Fowler
“Event Sourcing ensures that all changes to application state are stored as a sequence of events. Not just can we query these events, we can also use the event log to reconstruct past states, and as a foundation to automatically adjust the state to cope with retroactive changes.
The problem here lies with reliability. How can you rely on the architecture to make a change or publish a real-time event with respect to the changes in state of the application?
Event sourcing helps to come up from this situation by appending a new event to the list of the events every time a business entity changes its state. Entities like Customer may consist of numerous events. It is thus advised that an application saves a screenshot of the current state of an entity in order to optimize the load.
Event sourcing helps to come up from this situation by appending a new event to the list of the events every time a business entity changes its state. Entities like Customer may consist of numerous events. It is thus advised that an application saves a screenshot of the current state of an entity in order to optimize the load.
3. Command Query Responsibility Segregation (CQRS)
In a database-per-service model, the query cannot be implemented because of the limited access to only one database. For a query, the requirements are based on joint database systems. But how do we query then?
Based on the CQRS, to query single databases per service model, the application should be divided into two parts: Command and Query. In this model, command handles all requests related to create, update and delete while queries are taken care of through a materialized view. These views are updated through a stream of events. These events, in turn, are created using an event sourcing pattern which marks any changes in the data. These changes eventually become events.
Microservice Design Patterns for Seamless Deployment
When we implement microservices, there are certain issues which come up during the call of these services. When you design microservice architecture, certain cross-cutting patterns can simplify the working.
1. Service Discovery
The use of containers leads to dynamic allocation of the IP address. This means the address can change at any moment. This causes a service break. In addition to this, the users have to bear the load of remembering every URL for the services, which become tightly coupled.
To solve this problem and give users the location of the request, a registry needs to be used. While initiation, a service instance can register in the registry and de-register while closing. This enables the user to find out the exact location which can be queried. In addition, a health check by the registry will ensure the availability of only working instances. This also improves the system performance.
2. Blue-Green Deployment
In a microservice design pattern, there are multiple microservices. Whenever updates are to be implemented or newer versions deployed, one has to shut down all the services. This leads to a huge downtime thus affecting productivity. To avoid this issue, when you design microservice architecture, you should use the blue-green deployment pattern.
In this pattern, two identical environments run parallelly, known as blue and green. At a time only one of them is live and processing all the production traffic. For example, blue is live and addressing all the traffic. In case of new deployment, one uploads the latest version onto the green environment, switches the router to the same and thus implement the update.
Microservice Design Patterns for Performance Monitoring
Monitoring the performance is an important aspect for a successful microservice architecture. It helps calculate the efficiency and understand any drawbacks which might be slowing the system down. Remember the following patterns related to performance monitoring for ensuring a robust microservice architecture design.
1. Log Aggregation
When we refer to a microservice architecture we are referring to a refined yet granular architecture where an application is consisting a number of microservices. These microservices run independently and simultaneously as supporting multiple services as well as their instances across various machines. Every service generates an entry in the logs regarding its execution. How can you keep a track for numerous service related logs? This is where log aggregation steps in. As a best practice to prevent from chaos, you should be having a master logging service. This master logging service should be responsible for aggregating the logs from all the microservice instances. This centralized log should be searchable, making it easier to monitor.
2. Synthetic Monitoring a.k.a Semantic Monitoring
With the increase in load and microservices, it becomes important to keep a constant check on system performance. This includes any patterns which might be formed or addressing issues that come across. But more importantly, how is the data collected?
The answer lies with the use of a metric service. This metrics service is either in the Push form or the Pull form. As the name suggests, a Push service such as AppDynamics pushes the metrics to the service while a Pull service such as Prometheus pulls the data from the service.
3. Running a Health Check
Microservice architecture design promotes services which are independent of each other to avoid any delay in the system. But, there are times when the system is up and running but it fails to handle transactions due to faulty services. To avoid requests to these faulty services, a load balancing pattern has to be implemented.
To achieve this, we use ‘/health’ at the end of every service. This check is used to find out the health of the service. It includes the status of the host, its connection and the algorithmic logic.
No comments:
Post a Comment